Abstract
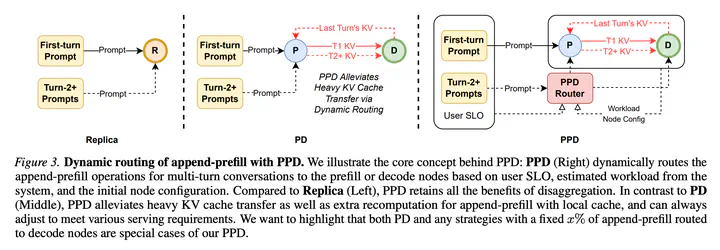
Prefill-Decode (PD) disaggregation has become the standard architecture for modern LLM inference engines, which alleviates the interference of two distinctive workloads. With the growing demand for multi-turn interactions in chatbots and agentic systems, we re-examined PD in this case and found two fundamental inefficiencies: (1) every turn requires prefilling the new prompt and response from the last turn, and (2) repeated KV transfers between prefill and decode nodes saturate the bandwidth, leading to high latency and even service degradation. Our key insight is that not all prefill operations are equally disruptive: append-prefill – processing only the new input tokens while reusing cached KV states – incurs substantially less decoding slowdown than full prefill. This motivates routing append-prefill to decode nodes locally. However, through comprehensive analysis, we show that no single fixed routing strategy satisfies all Service Level Objectives (SLOs) simultaneously. Based on this insight, we propose Prefill Prefill-capable Decode (PPD) disaggregation, a dynamic routing system that decides when to process Turn 2+ requests locally on decode nodes using cached KV states. PPD adapts to varying SLOs via configurable weights and seamlessly integrates with traditional PD deployments. With extensive evaluations, we show that PPD reduces Turn 2+ time-to-first-token (TTFT) by 68% while maintaining competitive time-per-output-token (TPOT), effectively alleviating KV transfer congestion under high load. We believe PPD represents a flexible and efficient paradigm for multi-turn LLM serving.
Jingyu Liu
CS PhD Student at Uchicago, Part-time Student Researcher at Together AI
My research interests include foundation models and efficient AI systems.
{kind=link}